I am not a developer. But learning how to use ImportXML has been one of the most interesting things I’ve done in the past few weeks.
If you haven’t heard of ImportXML yet, or just haven’t got around to using it, you need to learn it now.
Why?
– It’s not very hard
– It’s free and awesome
– It will save you tons of time if you do any work online and make you very happy! Yaaay
Assuming you work in the internet field, learning to code, even at a beginner/intermediate level, is a very valuable skill to have. You might never be the one writing complicated programs for your company, but you will understand what goes into it and how it works. Plus you’ll be able to create smaller “agile” tools that can make your life easier.
Pro tip: Learning a skill or theory is great, but applying it directly to one of your problems is the secret. It’s great to learn how to show all the dog breads in Gdocs using ImportXML, but you will most likely forget all the details of how it works once your done if you aren’t using it in your day-to-day activities.
Let’s get started..
ImportXML is a functionality inside Google Docs that allows you to make calls or queries out on the internet, without ever leaving the spreadsheet.
Lots of SEOs have written posts on how to build agile tools to get SEO work done, but ImportXML isn’t bias to the SEO world, you can do almost anything you can imagine with it.
Note : I’ve made a reference list at the end of this post for more on ImportXML with SEO
So let’s dig in… I’m going to show you how I helped my wife save hours for an assignment her boss wanted: Build a spreadsheet with every country, their population, GDP, & other data from multiple data sources online
Tasks
– Create a list of every country from CIA’s World Factbook.
– Get the page URL extension
– Get the full page URL
– Get the population
So we’re starting with this :

And need it to look like this :

She was going to do it by searching manually for this field

on 300+ pages, then copying all the information by hand!
Which made me say noooooooooooo!

… but I bet this kid would love it
So the fist step once you’re in Google Docs is to add the URL you’ll be using to cell A1. That way you can easily call on that URL in the ImportXML query with (A1,xxx) instead of (http://theurlIwant.com,xxx)

The first function we’re going to do with ImportXML is
=ImportXML(A1,”//ul[@class=’af’]//li”)
So how did I come up with that? Well you need to look at the data you need on the page then find it in the source code.
So this
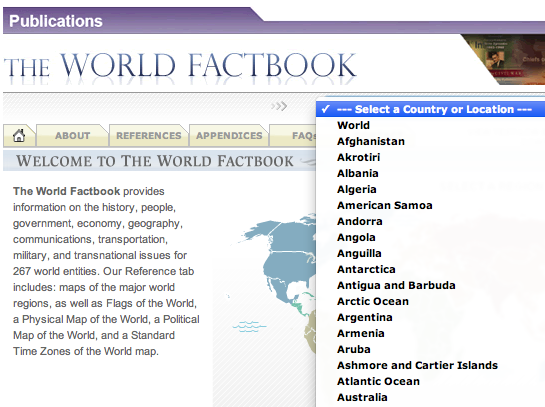
equals this in HTML
[sourcecode language=’html’]
- select a country or location
- World
- Afghanistan
- Akrotiri
- Albania
[/sourcecode]
If you’ve never written code or used ImportXML before, that query probably looking very complicated, but it’s not. Let’s break it down.=ImportXML(A1,”//ul[@class=’af’]//li”)
=ImportXML(url,query) is the structure of the command
URL
A1 is calling our original URL for the CIA world factbook site
Query
// – select all the elements of the following type
[@class=”] – only select the elements of this certain type
//ul – select all of the unordered lists
//ul[@class=’af’] – show me all unordered lists with class of ‘af’
//li – show all list items
//ul[@class=’af’]//li – show me all list items inside all the unordered lists that have a class of af
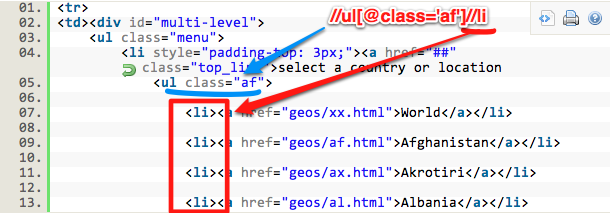
Next, I wanted to get the page-specific URL extension, like /countryname.html, because all the countries started with the same root: https://www.cia.gov/library/publications/the-world-factbook/
The ImportXML script I used to find that was=ImportXML(A1,”//ul[@class=’af’]//li/a/@href”)
The script is the same as before, because we’re looking for the same information, except we want to pull the info in the link (a href).
/a/@href works similarly to how //ul[@class=”] works to drill down in the code
Memorize this for the future to pull out URLs from web sites: “/a/@href”
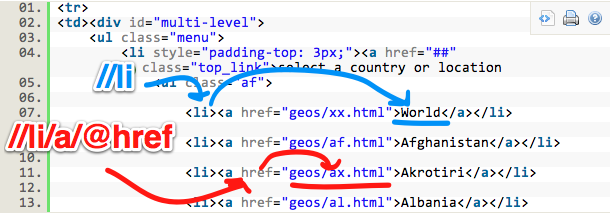
So now we have this
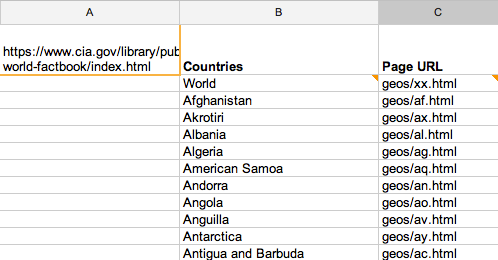
And we still need the full URL and population data.
To combine the page specific URL and root URL I used ” =CONCATENATE($A$2,D2) ” and replicated it down the page.
CONCATENATE combines two fields into one — so I made field A2 “https://www.cia.gov/library/publications/the-world-factbook/” (without /index.html at the end) and added the country page to it to form the full URL.
The first time I did it, I used =CONCATENATE(A2,D2) and copied it down the page. It totally broke. Why? Because I left out the two $ symbols.
$ holds the spot in the query and doesn’t make it relative to the cell, it makes it ‘fixed’. So when I copied the formula down the sheet WITHOUT $ it essentially wrote this for me :
A2,D2
A3,D3
A4,D4
A5,D5
and so on…
When really I needed this :
A2,D2
A2,D3
A2,D4
A2,D5
because I always need the first part of the query to be the URL in cell A2.
With the dollar sign working correctly, row 5 looks like this : =CONCATENATE($A$2,D5)The hard part
The last thing I needed to mark off this great accomplishment was the population data for every country.
Up until now I had really just set myself (or my spreadsheet) up to do work, but it hadn’t done any yet.
So let’s go back and find some population data on the page so we can find it in the HTML

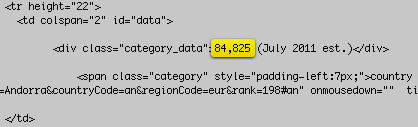
Long story short – I couldn’t get the population data.
Why not?? Should the query be //div[@class=’category_data’]
Yes it should be, but the CIA has done a HORRIBLE job at marking up their site. They should have used unique section names in their html, but instead they made all data “category data” so you cannot get back the response you’re looking for.
Hmm.. ok well on the w3schools xpath page it says you can use [number] to select just a certain result like //div[9] for the 9th div which has the population data.
But it didn’t work!

Just when I thought it was over… Chris Le from SEER Interactive to the rescue!
Chris discovered that Google Docs does NOT support Xpath 2.0 fuctionalities, only 1.0. So the div[9] thing was never going to work.
Instead Chris wrote an awesome script to do the same thing for me!
[sourcecode language=”xml”]
/**
* From an input array, filter by regEx, and return the first integer values
* found within.
*
* @param {cells} inputArray Range of cells you want to filter
* @param {string} regEx Regular expression to filter by
* @author Chris le (@djchrisle)
*
* @example
*
* =findIntegerInCells(A1:A10, “,\d.*est\.\)”)
*
* Looks in cells A1 to A10 for a comma, followed by a number, then anything
* and followed by “est.)”
*/
function findIntegerInCells(inputArray, regEx) {
var retVal = [];
// Look for cells that match the regular expression
for (var i = 0; i < inputArray.length; i++) { if (inputArray[i].toString().match(regEx)) { retVal.push(inputArray[i]); } } if (retVal.length > 0) {
// Take the first thing found, remove commas
var value = retVal[0].toString().replace(/,/g, ”);
return parseInt(value); // Return just the numeric value
} else {
return ‘Nothing found : (‘;
}
}
[/sourcecode]
He created this scripted called findIntegerInCells under Tools > Script editor inside Google Docs. Then to get the population data, you need to use the function =findIntegerInCells(importXml(E3, “//div[@class=’category_data’]”), “,\d.*est\.\)”) in a new cell.
Since almost every population on the CIA site has est. after it, he used that in conjunction with the URLs I made to find the right area and grab the numbers for population.
And it worked like a charm!
He even put a line in there so that if it can’t find population data (ex. indian ocean, antarctica, etc) it doesn’t error out, it puts Nothing found 🙁
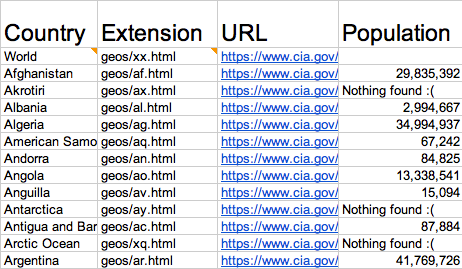
Final productI realize this wasn’t the most complicated problem faced or tool built using ImportXML, but I sure learned a lot about it’s features and how to make it give me what I want.
I had to do a lot of reading, digging around Google and trial and error, but I feel much more confident now about building my own tools for SEO, and I hope you will too!
If you have any questions I’d love to help in any way I can. There are a lot of other great people in the industry who I’m sure would lend a hand as well.
Thanks again Chris!
Note :
Chris Le of SEER Interactive just wrote a great post and script to fix the new Google SERP scrapping issue with ImportXML. If you’re trying to scrape the SERPs, you need his hack.
Killer ImportXML Resources :
These posts below do an exceptional job of explaining ImportXML and demonstrating various uses for it. You’ll have a great understanding if you go through a few of these.
How To Build Agile SEO Tools Using Google Spreadsheets
http://www.distilled.net/blog/seo/how-to-build-agile-seo-tools-using-google-docs/
Playing Around with ImportXML in Google Spreadsheets
https://seogadget.co.uk/playing-around-with-importxml-in-google-spreadsheets/
ImportXML Cookbook
http://www.seerinteractive.com/blog/importxml-cookbook
The ImportXML Guide for Google Docs
http://www.distilled.net/blog/distilled/guide-to-google-docs-importxml/
Killer ImportXML Tools
Guest post opportunity finder tool
http://skyrckt.com/guestposttool – James Agate – Skyrocket SEO
Keyword research with Ubersuggest and ImportXML – Dan Shure – Evolving SEO
Do you have an awesome ImportXML tool? Add it to the list!
14 Replies to “[Tutorial] Learn ImportXML – Best SEO Tool Ever”
Comments are closed.


=ImportXML(A1,”//ul[@class=’af’]//li”) -> tried everything but I alawys get an #ERROR!
You know why?
That query is designed to work specifically with the example URL in the tutorial above (ie. the CIA world book website), which uses class markups in their html. That’s why I used [@class=’af’] to target a specific part on the page, then search the //li inside of it.
If you are using a different URL (reference in cell A1) it most likely won’t work, unless that page is also using classes and has an “af” class in the html.
Let me know what you’re trying to pull and from where and hopefully I can help out with more specifics.
Hi Jordan, thanks for the nice tutorial! Very useful!
However the cases are two: I’m either wrong or you made a little mistake. In particular, when explaining the =CONCATENATE part you refer to the “D” column, probably meaning the “C” one. Do you? Otherwise I don’t think it makes any sense. But, again, it’s possibly me who has not understood something of the process.
Thank you again!
Peace.
In other similar cases, the Xpath # does work but you need to use index outside of importXML
For the problem I’m doing, this formula =index(importxml(A2,”//div[@class=’description’]//p[1]”)) returns me the 1rst p in each div with the class of description. With [2] it returns me the second one, and so on..
In your example, the information you need is within the div attributes so I don’t know how that works without the script Chris wrote you.
Hi! Thanks for the wonderful article but unfortunately I am still having a problem with my project. I need to extract the “AP” information from the following document http://img824.imageshack.us/img824/3640/xpath.jpg
. I will appreciate your help! Thanks
Awesome tutorial. The only problem I have is that when the spreadsheet refreshes, it runs the formula again, and that time it does not work. I think this might have to do with the fact that the values that I am referencing update every few minutes – though my URL does not change and the class names do not change so I’m not sure why it breaks when it refreshes. Any thoughts?
for reference, the page I am pulling data from is a search on socialmention.com such as:
http://www.socialmention.com/search?q=seo&t=all&btnG=Search
hi
hi.. compliments for your job
can you tall me how i can extract the image url ?
importxml(a1,//img@src) dont work
can you help me?
I want to use importxml in a google spreadsheet to collect google search results for different queries in a list. I got it working, but only as far as returning local results. I need to collecte the same search results as when I do a google search manually with geosurf to another coubtry, e.g. Denmark going to google.dk. When you search from google.dk the number of results with geosurf are different than google.dk without geosurf. I am trying to do it with a VPN connection, but I still only get the results that correspond to non-geosurf.
So it is starting to look like the url goes out from the server, not the client that is on the VPN.
Can you help me understand how the url is send out, and from where? Any idea how I can make it work the way I want?
Thanks
Bent
Hi Jordan,
Thanks for the great article … very useful.
For the application I had in mind I need each importxml query to put the retrieved code into a single cell. For example when tarting a bullet list at the moment it is:
– outputting to multiple cells horizontally (columns) when targeting ul
– outputting to multiple cells vertically (rows) when targeting li
Is it possible, using a gsheet formula or xpath code, to get it to output the li elements into a single cell. Ideally with a comma separator between elements? Or without a separator, as complete text would be better than multiple cells?
Thanks
Nick